Web scrapping with python BeautifulSoup
Dig out web Data .
URL used: http://www.thehindu.com/news/
With this script i am going to dig data of The hindu news service of india . It will bring you what are the recent news published in this news website .

I am going to bring only those news which are latest , i have marked as round .
import os,requests
from bs4 import BeautifulSoup
r=requests.get('http://www.thehindu.com/news/')
file=BeautifulSoup(r.content)
os.system('clear')
print "Bellow are recent news with time and headlines."
print file.find_all("div",{"class":"headlines"})[0].text
print "\n\nBellow are the links for the above news , visit for more info:\n\n"
for i in file.find_all("div",{"class":"headlines"})[0].find_all('a'):
print i.get('href')
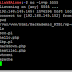
Out of my script is as bellow :

Next i will scrap data from another site . I will dig out all the link and download Picture that is available in any website .
Dig out web Data .
URL used: http://www.thehindu.com/news/
With this script i am going to dig data of The hindu news service of india . It will bring you what are the recent news published in this news website .
I am going to bring only those news which are latest , i have marked as round .
import os,requests
from bs4 import BeautifulSoup
r=requests.get('http://www.thehindu.com/news/')
file=BeautifulSoup(r.content)
os.system('clear')
print "Bellow are recent news with time and headlines."
print file.find_all("div",{"class":"headlines"})[0].text
print "\n\nBellow are the links for the above news , visit for more info:\n\n"
for i in file.find_all("div",{"class":"headlines"})[0].find_all('a'):
print i.get('href')
Out of my script is as bellow :
Next i will scrap data from another site . I will dig out all the link and download Picture that is available in any website .




No comments:
Post a Comment